
Как работает поисковая машина
Поисковые системы можно сравнить со справочной службой, агенты которой обходят предприятия, собирая информацию в базу данных (рис. 4.21). При обращении в службу информация выдается из этой базы. Данные в базе устаревают, поэтому агенты их периодически обновляют. Некоторые предприятия сами присылают данные о себе, и к ним агентам приезжать не приходится. Иными словами, справочная служба имеет две функции: создание и постоянное обновление данных в базе и поиск информации в базе по запросу клиента.

Рис. 4.21. Поисковые системы можно сравнить со справочной службой, агенты которой обходят предприятия, собирая информацию в базу данных
Аналогично, поисковая машина состоит из двух частей: так называемого робота (или паука), который обходит серверы Сети и формирует базу данных поискового механизма.
База робота в основном формируется им самим (робот сам находит ссылки на новые ресурсы) и в гораздо меньшей степени - владельцами ресурсов, которые регистрируют свои сайты в поисковой машине. Помимо робота (сетевого агента, паука, червяка), формирующего базу данных, существует программа, определяющая рейтинг найденных ссылок.
Принцип работы поисковой машины сводится к тому, что она опрашивает свой внутренний каталог (базу данных) по ключевым словам, которые пользователь указывает в поле запроса, и выдает список ссылок, ранжированный по релевантности.
Следует отметить, что, отрабатывая конкретный запрос пользователя, поисковая система оперирует именно внутренними ресурсами (а не пускается в путешествие по Сети, как часто полагают неискушенные пользователи), а внутренние ресурсы, естественно, ограниченны. Несмотря на то что база данных поисковой машины постоянно обновляется, поисковая машина не может проиндексировать все Web-документы: их число слишком велико. Поэтому всегда существует вероятность, что искомый ресурс просто неизвестен конкретной поисковой системе.
Эту мысль наглядно иллюстрирует рис. 4.22. Эллипс 1 ограничивает множество всех Web-документов, существующих на некоторый момент времени, эллипс 2 - все документы, которые проиндексированы данной поисковой машиной, а эллипс 3 - искомые документы.
Таким образом, найти с помощью данной поисковой машины можно лишь ту часть искомых документов, которые ею проиндексированы.
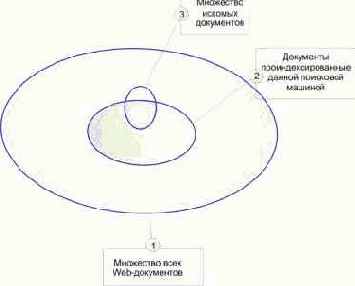
Рис. 4.22. Схема, поясняющая возможности поиска
Проблема недостаточности полноты поиска состоит не только в ограниченности внутренних ресурсов поисковика, но и в том, что скорость робота ограниченна, а количество новых Web-документов постоянно растет. Увеличение внутренних ресурсов поисковой машины не может полностью решить проблему, поскольку скорость обхода ресурсов роботом конечна.
При этом считать, что поисковая машина содержит копию исходных ресурсов Интернета, было бы неправильно. Полная информация (исходные документы) хранится отнюдь не всегда, чаще хранится лишь ее часть - так называемый индексированный список, или индекс, который гораздо компактнее текста документов и позволяет быстрее отвечать на поисковые запросы.
Для построения индекса исходные данные преобразуются так, чтобы объем базы был минимальным, а поиск осуществлялся очень быстро и давал максимум полезной информации. Объясняя, что такое индексированный список, можно провести параллель с его бумажным аналогом - так называемым конкордансом, т.е. словарем, в котором в алфавитном порядке перечислены слова, употребляемые конкретным писателем, а также указаны ссылки на них и частота их употребления в его произведениях.
Очевидно, что конкорданс (словарь) гораздо компактнее исходных текстов произведений и найти в нем нужное слово намного проще, нежели перелистывать книгу в надежде наткнуться на нужное слово.